【勾配ブースティングとは】
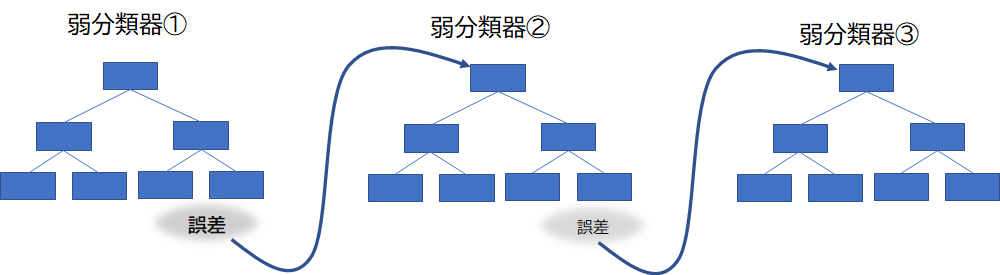
弱分類器を複数重ねて精度を上げていく手法。前の弱分類器の予測誤差を次の新しい弱分類器は引き継いで誤差を小さく調整していく。
【要点】
•現在最も利用されている機械学習アルゴリズムのひとつ 。
•高速かつ高精度であるためKaggleなどのコンペティションの上位解法の常連 。
•アンサンブル学習の手法のひとつで、ブースティングを損失関数の勾配を用いて拡張したもの。
•Scikit-Learn、XGBoost、LightGBM、CatBoostなどのパッケージから簡単に利用できる。
【学習手順】
勾配ブースティングの学習手順は、大きくは以下の手順で行います。
1.最初の弱識別器を本来の目的変数にフィットさせる(最初の予測に目的変数の平均をとる場合もある)
2.弱識別器の数だけ以下の手順を繰り返す
2-1. 各学習サンプルの損失関数の勾配を求める
2-2. 損失関数の勾配に弱識別器をフィットさせる
2-3. 構築した弱識別器の予測結果を用いて再び1に戻る
基本的に直前の予測ありきの学習方法であるため、①で最初の予測を行うための弱識別器を構築し、とりあえず直前の予測結果があれば学習が進められるため、最初の予測には目的変数の平均値を利用することもあります。
②では各弱識別器の学習を行いますが、まずは弱識別器をフィットさせる損失関数の勾配を計算し、その勾配を利用して弱識別器の学習を実施。この識別器を用いて各サンプルに対する予測を行い、次の弱識別器で利用される勾配の計算に必要な予測値を更新します。
このステップを構築する弱識別器の数だけ繰り返すことで、勾配の値がゼロに近づき、損失関数を最小化するモデルを構築することができます。
また勾配ブースティングを拡張した手法では損失関数の近似を行うために勾配だけでなくヘシアンを利用したり、連続的な変数をビニングすることで離散値として扱い、ノード分割を高速化するなどの工夫が行われています。
参考文献:https://aizine.ai/glossary-gradient-boosting/#toc3